- The prompt text
- The platform and region
- Whether you were mentioned
- Your position/rank when mentioned
- The response (or a response snippet)
- Citations (domains/URLs), when available
- Sentiment signals extracted from the response
AI answers change. Sometimes they change because the model changed. Sometimes they change because the sources changed. Sometimes they change because the prompt is ambiguous. Meridian is built to make that variability usable, so you can measure performance reliably and improve it over time. This page explains what Meridian records, why the same prompt can look different day to day, and how to use the data without overreacting to noise.
What Meridian runs (and what a “response” means)
Meridian tracks your prompts over time across AI platforms (and often regions). Each time a prompt is executed, Meridian records a response.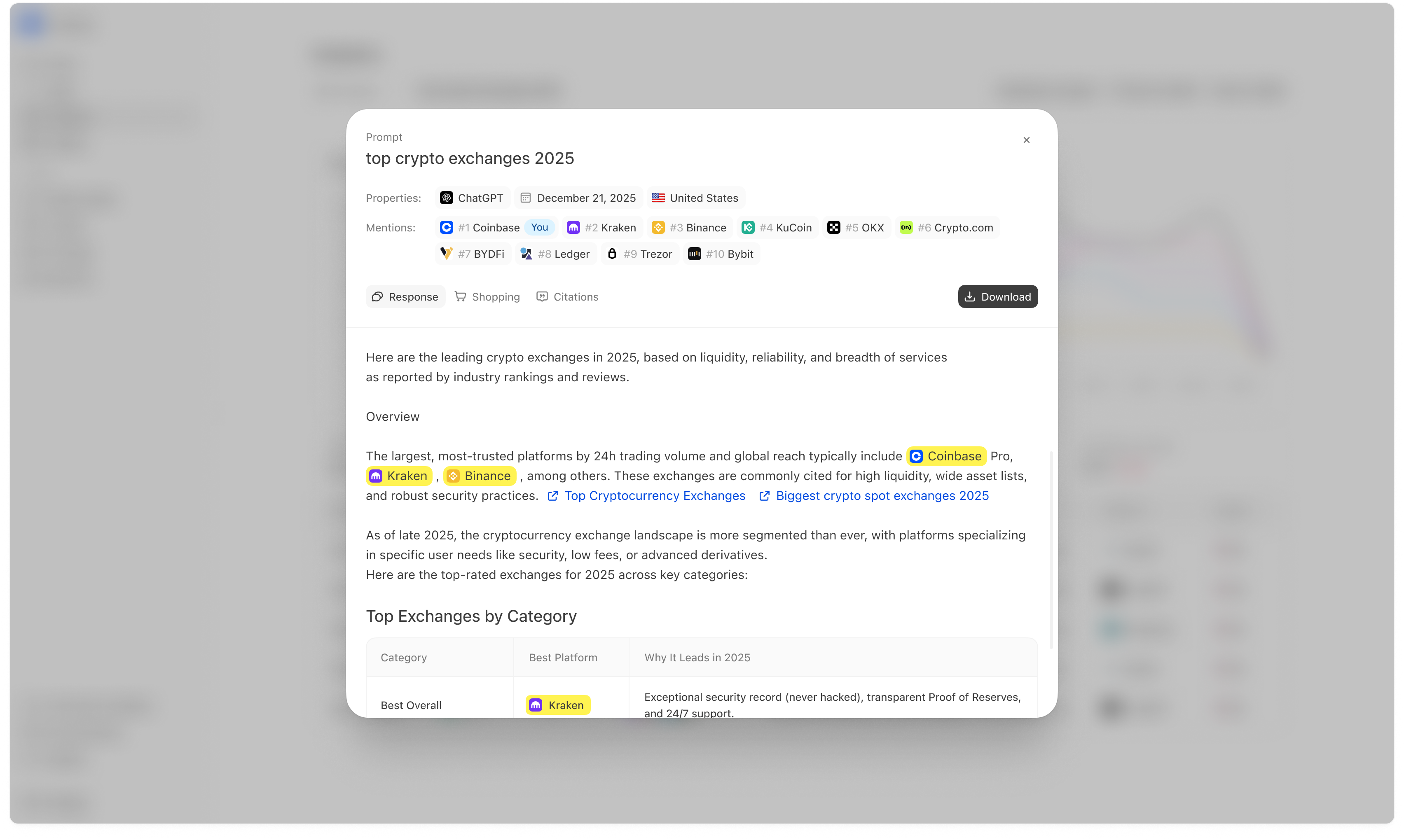
- the prompt text,
- the platform (ChatGPT, Gemini, Perplexity, AI Overviews / AI Mode, etc.),
- the region,
- the response from the AI assistant,
- and the date/time it was run.
What Meridian captures from a response
From each response, Meridian captures evidence that you can inspect later, including:- Mentioned vs not mentioned: whether your brand appeared in the answer.
- Position / ranking: where you appeared if the answer is list-like (#1, #2, etc.).
- The answer text: the response (or a snippet), so you can see exactly what was said.
- Citations: domains and URLs referenced, when the platform provides them.
- Sentiment signals: narrative cues extracted from the answer across dimensions (fees, reliability, security, etc.).
Why the same prompt can change day to day
It is normal for answers to vary across days. Common reasons include:The platform chooses different sources
If the model is retrieval-based, it may cite different URLs on different days. That can change which brands are included and who ranks first.The platform changes model behavior
AI platforms ship updates frequently. Output style and ranking logic can shift.The prompt has multiple valid interpretations
For example, “best crypto exchange” could be interpreted by fees, security, geography, or product features. Slight differences can change the ranked list.The ecosystem changes
Competitors publish new content, new editorial pages appear, and community conversations shift. Those changes can affect citations and rankings.One run is best used for investigation. A week of runs is best used for decisions. Meridian is designed to emphasize the second.
Technical approach: API access vs UI scraping
AI platforms often behave differently depending on how you access them. Some tools provide APIs, but API outputs can differ from what real users see in the product UI (and citation behavior can differ as well). In addition, some platforms do not offer stable public APIs for the exact experience users interact with. Meridian’s goal is simple: measure what your customers see as closely as possible, consistently, and at scale.Why Meridian doesn’t rely on APIs alone
Using only APIs can introduce gaps such as:- Different outputs: API responses can differ from UI responses in tone, structure, and ranking behavior.
- Different sourcing: Citations and retrieval can vary between API and UI experiences.
- Limited coverage: Some platforms or product experiences are not fully represented through public APIs.
How Meridian keeps data consistent
Depending on the platform, Meridian uses methods designed to reflect a consistent “typical user” experience and capture results in a repeatable way. The goal is to reduce noise, reflect realistic outputs, and make trends meaningful when you compare weeks. > In practice: you should treat a single day as a snapshot, and treat week-over-week patterns as the best signal for decisions.How Meridian turns variability into useful signals
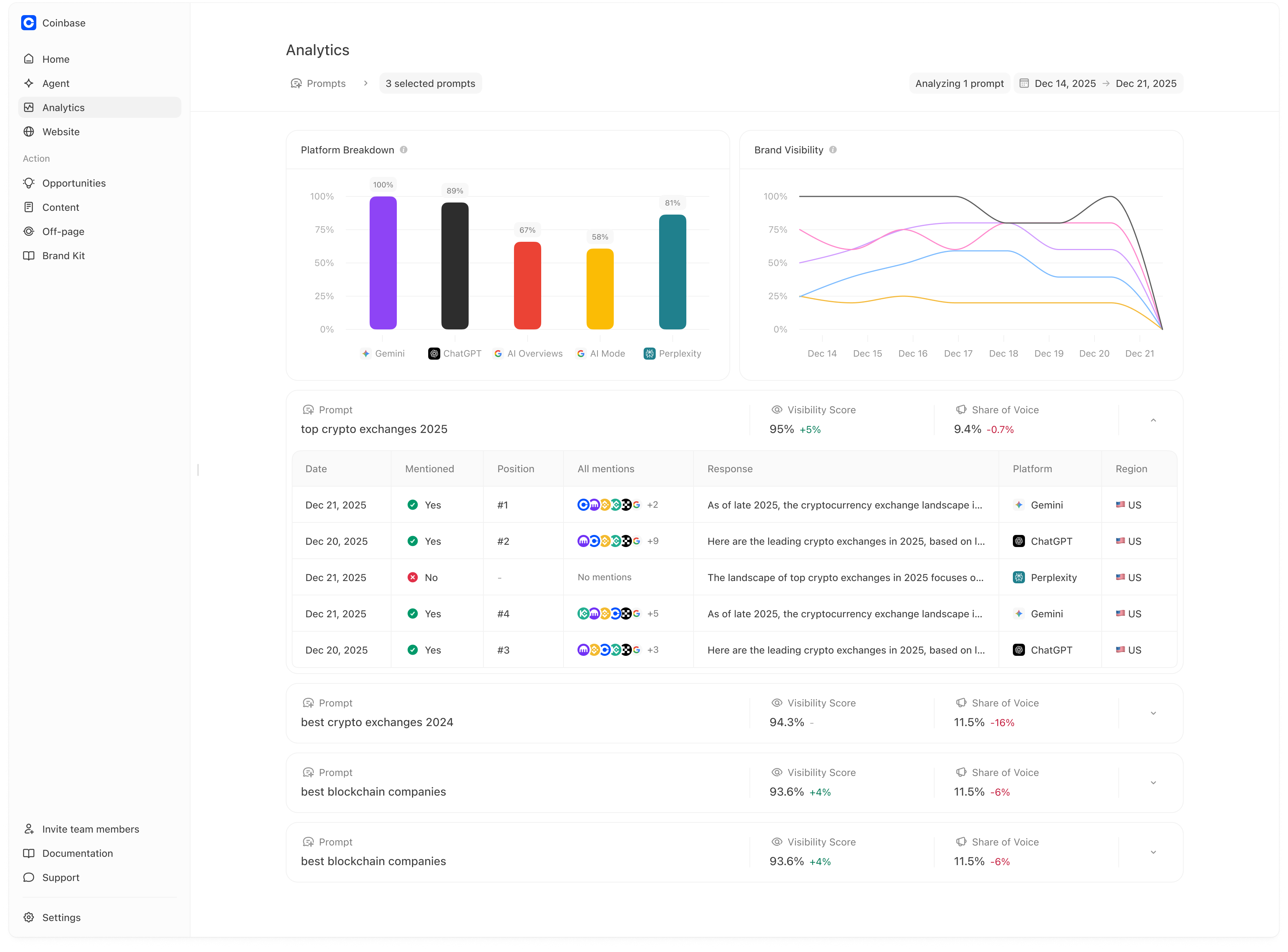
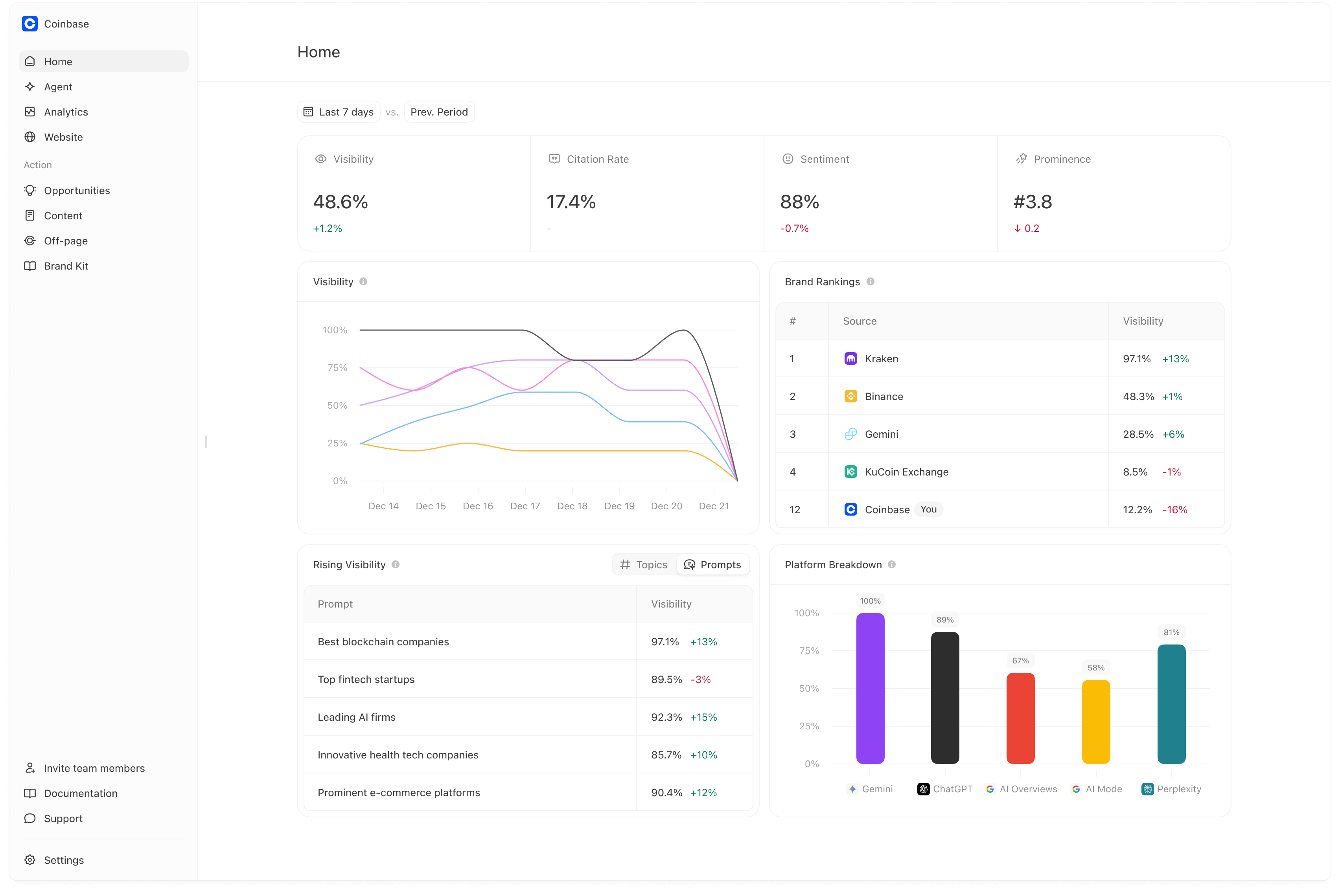
Meridian makes daily variation useful by aggregating runs into:Home KPIs (weekly scoreboard)
- Visibility
- Citation Rate
- Sentiment
- Prominence
Analytics tabs (drivers)
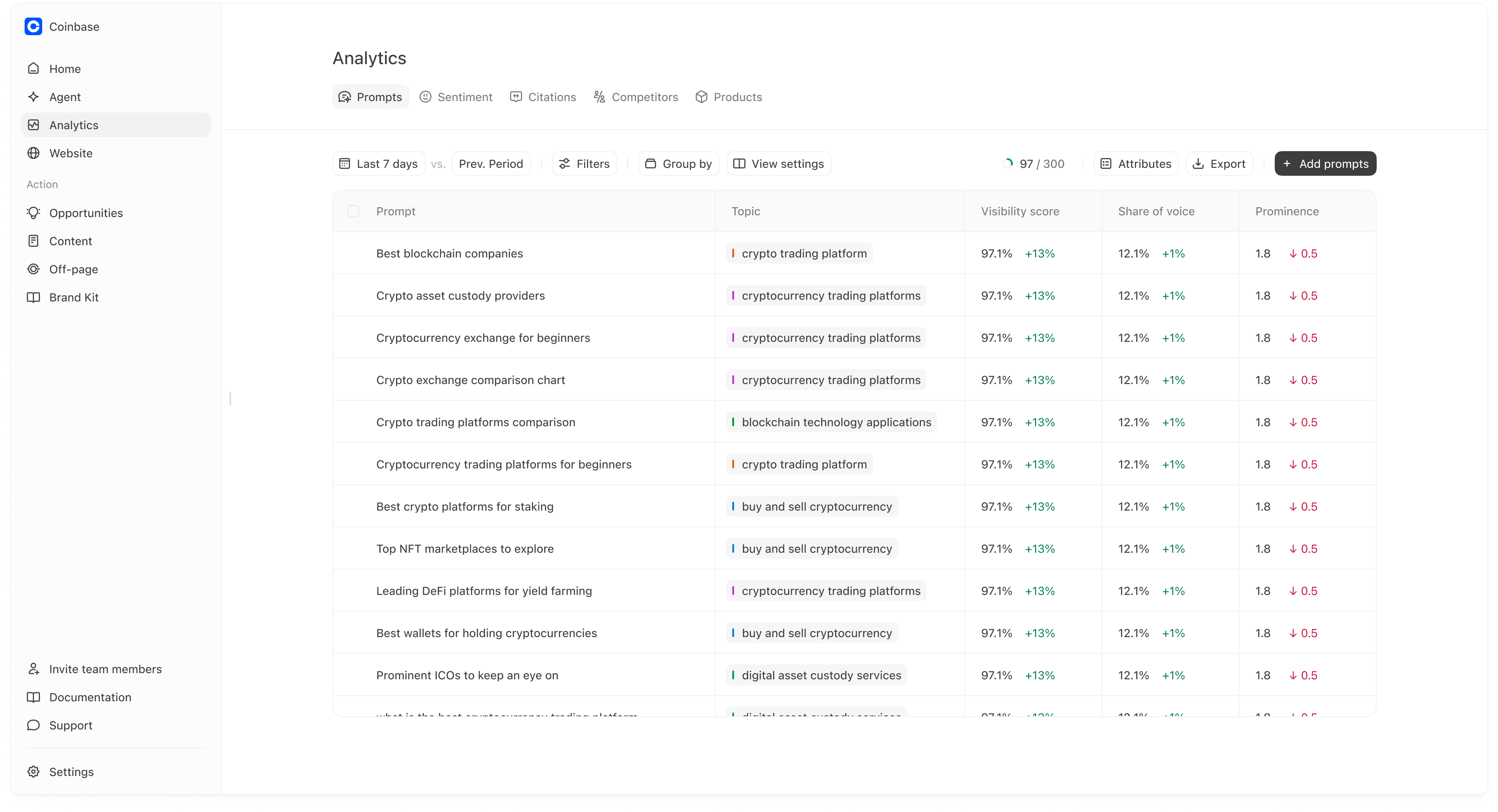
- Prompts: which prompts you win/lose and how that changes
- Sentiment: which narratives help/hurt you
- Citations: which sources drive answers and where you are missing
- Competitors: who is winning and on what prompts/topics
- Products: which products are recommended or missing
Action surfaces
- Opportunities: what to create next based on gaps
- Content: briefs and articles designed to improve performance
- Off-page: editorial/community targets where inclusion can improve trust
How to interpret “spikes” and “drops”
A practical approach:- If something changes on one day only, treat it as a signal to inspect (open that run), but avoid large strategic changes.
- If something changes consistently across a few weeks, treat it as a trend and choose an action.
- check whether filters/time range changed,
- check whether the platform breakdown suggests it was one platform,
- then inspect the citations used in losing runs.
How to validate whether an improvement “worked”
Improvements typically show up as:- You are mentioned more often on the target prompts (visibility up for those prompts).
- You move higher in the list (prominence improves).
- Your owned pages appear more often as citations (owned share increases).
- Negative narratives decrease in the relevant sentiment dimension.
For the cleanest measurement, pick a small set of “target prompts” before making changes. Then track those prompts for one or two periods after publishing/fixes.Visibility changes aren’t instantaneours. Improvements can take weeks to months to appear, and no single improvement is guaranteed to affect visibility.